scrapy是通过直接模拟HTTP请求的方式进行页面抓取,这种方式与Requests库类似,是无法抓取JavaScript动态渲染页面的,在这一节,我们通过对“爱彼迎民宿网”(zh.airbnb.com)的抓取,来介绍Scrapy与Selenium的对接,只要成功实现了这个对接,Scrapy也就做到了“可见即可爬”,可以处理任何网站的抓取。(本文以FireFox为例,若是其他浏览器也是大同小异)
0x00 配置
首先常规操作安装selenium库 :
import无异常后我们需要前往https://github.com/mozilla/geckodriver/releases下载最新版本的GeckoDriver以实现Selenium对FireFox的驱动。
将下载的GeckoDriver文件拖入Python的Scripts目录中,然后执行以下Python代码做一下测试,若成功弹出一个空白的FireFox浏览器则证明所有配置都已完成,可以进行下一步操作。
1
2
|
from selenium import webdriver
browser = webdriver.Firefox()
|
0x02 网站分析
首先明确任务:爬取“爱彼迎”网站上主流城市的房源信息,先来观察它们的url构成
https://zh.airbnb.com/s/homes?refinement_paths%5B%5D=%2Fhomes&query=BeiJing&allow_override%5B%5D=&s_tag=kYQ_4ODi§ion_offset=7&items_offset=36
首先,可以很直观的看出,query参数是控制所要查询的城市地名的,而多观察几个例子,也不难看出item_offset是控制分页的,但是该参数控制分页并不是以+1来递增的。至于另外几个参数,很难直接看出它们的作用,不过没关系,我们进行一下“必要开路”,修改一下url,去掉其他参数,只留一个城市,看看网站访问是否正常。访问:https://zh.airbnb.com/s/homes?query=BeiJing后,我们可以看到,该网站自动的将url补齐了,访问了北京城市房源的第一页。

了解到该网站这个特性后就容易处理了,我们只需要重写**start_requests(self)**方法 ,枚举城市并不断通过“下一页”按钮,获得下一页的分页url,不断构造Request请求即可完成网站的爬取。
0x10 初始化项目
1
2
3
4
5
|
scrapy startproject airbnb
cd airbnb
scrapy genspider house zh.airbnb.com
# 修改settings.py
ROBOTSTXT_OBEY = False
|
然后定义Item,为了使获取到的Item各字段均为str类型,这里使用输出处理器函数进行合成
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
from scrapy import Item,Field
from scrapy.loader.processors import Join, MapCompose, TakeFirst
class AirbnbItem(Item):
# define the fields for your item here like:
name = Field(
output_processor=Join(),
)
style = Field(
output_processor=Join(),
)
price = Field(
output_processor=Join(),
)
city = Field(
output_processor=Join(),
)
url = Field(
output_processor=Join(),
)
|
0x11 start_requests(self)
根据网站分析得到的思路,我们将想要爬取的城市写在settings.py中的CITIES列表中,然后重写**start_requests()**方法构建各城市的初始页面Request。
1
2
3
4
5
|
def start_requests(self):
for city in self.settings.get('CITIES'):
start_url = 'https://zh.airbnb.com/s/homes?query='+city
yield Request(url=start_url,callback=lambda response,city=city:self.parse(response,city))
|
0x20 对接Selenium
Scrapy与Selenium的对接是通过Downloader Middleware实现的,我们需要在Middlewares.py中写一个类,并在**procsee_request()**方法里对每个抓取的请求进行处理,启动浏览器并进行页面渲染,再将渲染后的结果构造成一个HTML Response对象返回。一下附上代码实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from scrapy.http import HtmlResponse
class SeleniumMiddleware():
def __init__(self,timeout=None):
self.timeout = timeout
self.browser = webdriver.Firefox()
self.browser.implicitly_wait(self.timeout) #设置隐式等待
self.wait = WebDriverWait(self.browser,self.timeout) #设置显式等待
def __del__(self):
self.browser.close() #对象被被Python解释器释放对象的时候默认调用__del__方法,实现关闭浏览器功能
def process_request(self,request,spider):
'''
用FireFox抓取页面
:param request:Request对象
:param spider:Spider对象
:return:HtmlResponse
'''
try:
self.browser.get(request.url)
self.wait.until(EC.presence_of_element_located((By.XPATH,'//span/div/ul\[@class="_11hau3k"\]'))) #根据分页控制器加载成功为标志判断网页加载完成
return HtmlResponse(url=request.url,request=request,body=self.browser.page_source,encoding='utf-8',status=200)
except TimeoutException:
return HtmlResponse(url=request.url,request=request,status=500) #超时异常处理
@classmethod
def from_crawler(cls,crawler):
return cls(timeout=crawler.settings.get('SELENIUM_TIMEOUT'))
|
在**init()方法中我们对对象做了初始化,比如打开浏览器,设置显/隐式等待时间(由settings.py中的 SELENIUM_TIMEOUT 关键字控制),而del()**方法则会在对象被被Python解释器释放对象的时候默认调用,这里实现了一个关闭浏览器的功能。在process_request()方法中,我们通过显式等待方法wait.until判断分页控制的加载状况,若是分页控制器加载出来了,则判定网页已经完成渲染,构造一个HTML Response对象并返回。HtmlResponse对象是Response的一个子类,构造这个对象时需要传入多个参数,如url,body等,这里的body我们需要传回渲染成功后的网站源码给Spider进行解析,而源码保存在page_source类变量中,将其传给body参数即可。这里附上Html Response对象结构的官方文档:http://doc.scrapy.org/en/latest/topics/request-response.html
然后,这样就完成了???没错,就是完成了。根据Scrapy Middleware的特性,若是中间件的返回值是一个Response对象,更低优先级的Downloader Middleware的**process_request()和process_exception()方法就不会再调用,转而开始执行每个Downloader Middleware的process_response()**方法,调用完毕后直接将response发送给Spider进行解析。也就是我们通过这个下载中间件替换了内置的默认下载器。这便是Downloader Middleware实现Selenium对接原理。
0x30 页面解析
获得到的response会传给Spider内的回调函数进行解析,下一步我们需要实现回调函数,这个网站的前端写的很乱,很考验各位的Xpath熟练度,这里不对页面内容的解析做过多的介绍,直接附上代码实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
def parse(self, response, city):
# 这是设置info等级的日志输出
self.logger.info('已爬取 %s 网址的响应' % response.url)
info_houses = response.xpath('//div\[@itemprop="itemListElement"\]')
for house in info_houses:
#print(house.extract())
loader = ItemLoader(AirbnbItem(),response=response)
loader.add_value('name',house.xpath('./meta\[@itemprop="name"\]/@content').extract_first().replace('- undefined -',''))
loader.add_value('style',house.xpath('.//a\[@class\]//span\[@class="_14ksqu3j"\]/span//text()').extract())
loader.add_value('price',house.xpath('./div//span/span/span\[@class="_9nurmxj"\]/span\[@class="_9nurmxj"\]/..//text()').extract())
loader.add_value('city',city)
loader.add_value('url',house.xpath('./meta\[@itemprop="url"\]/@content').extract_first())
item = loader.load_item()
print(item)
yield item
next_page = response.xpath('//li\[@class="_b8vexar"\]/a\[@class="_5u96sq" and @aria-busy="false"\]/@href').extract_first()
if next_page != None:
yield Request(url=self.base_url+next_page,callback=lambda response,city=city:self.parse(response,city))
|
整个项目完成了,执行 scrapy crawl house 命令即可开始抓取。
0x40 修改日志等级
启动抓取后,我们可以看到一切进行顺利,但是输出了很多很多很多乱七八糟的东西。
虽然这些东西的输出似乎不影响整个项目的运行,但是笔者总是感觉很不爽,为什么要输出这些东西啊。笔者将其输出日志保存下来观察发现这个像是网站的源码,查了资料发现在对接过程中Scrapy框架会以DEBUG等级日志输出渲染完成的网页源码。想要解决这个问题,首先我们需要先了解一些Scrapy日志等级,在Scrapy中,日志被分为5个等级,默认指定的等级是最低级的DEBUG,也就是DEBUG及DEBUG以上等级的日志会被输出,若是人为将输出等级提高,比如提高到ERROR级,那么只会输出ERROR级及其以上的等级。
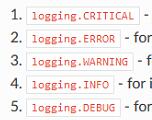
根据这个特点,我们可以通过修改Scrapy输出日志等级来去除这些输出。有两个方法可以实现这个功能:
第一个是在settings.py中修改本项目的日志输出等级,只需要在最后加上一行即可
1
|
LOG_LEVEL = 'INFO' #设置日志输出等级,INFO及INFO以上等级的日志会被输出(即忽略DEBUG等级日志)
|
第二种方法是通过参数修改本次输出日志最低等级,也就是在执行命令时采用这条命令:
1
|
scrapy crawl -L INFO house
|
通过这两种方法,便可以成功解决对接时输出大量垃圾信息的问题了。
Scrapy对接Selenium教程到此结束,在下一节中会介绍更高效的页面渲染方法。
若是各位对Python学习有什么心得体会欢迎联系**Mail:root@qfrost.com**与我联系。