0x00 需求分析
虽然基于Scrapy框架,我们可以轻易实现异步的、高并发的爬虫,但是,无论如何高并发,计算机的带宽永远是恒定的,协程设计的再巧妙也顶多是把带宽跑满,要是一个站实在太大太大了,就算把带宽跑满也要爬很久很久那该怎么办呢?
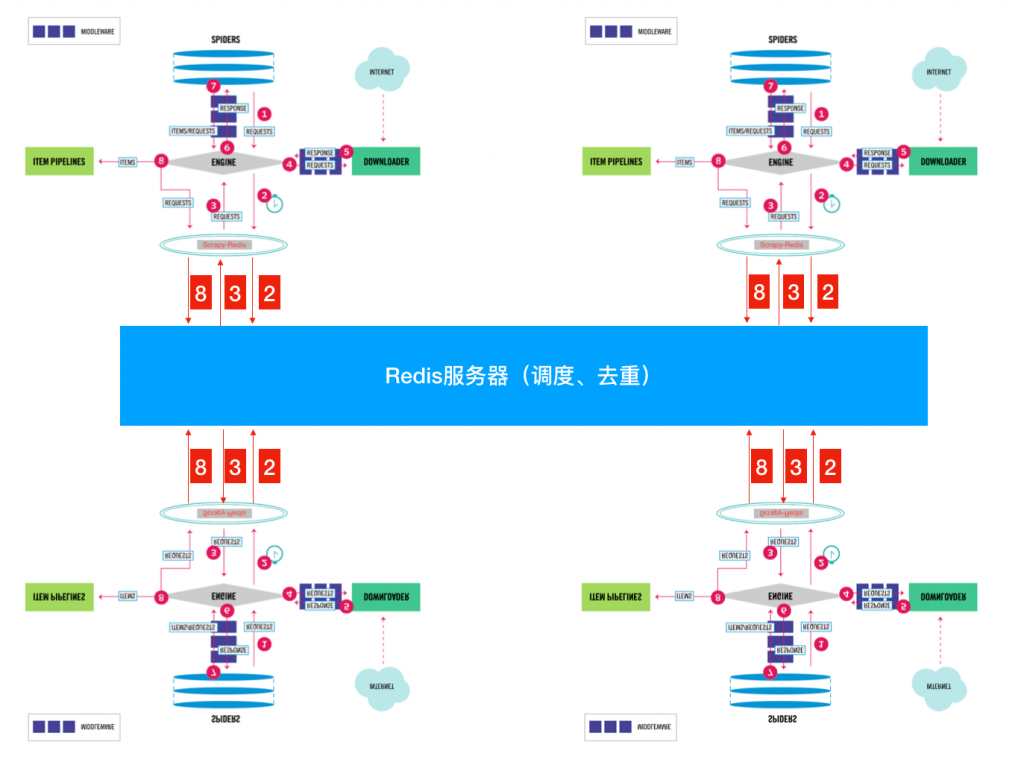
这就需要设计分布式的爬虫,通过多台计算机来爬取,这样不仅可以成倍的增加爬取效率,还可以让我们适当增加单台计算机的爬取间隔时间,以降低被禁IP的风险。那么要实现分布式的爬虫架构,需要我们首先解决两个问题:
- 要实现协同爬取,首先要替换Scheduler,以共享各台计算机的爬取队列。
- 多台计算机需要共享指纹库,以实现去重。
共享的爬取队列和指纹库可以通过建立一个数据库在一台各计算机均能访问到的服务器上来实现,而这两样东西的共享意味着各台计算机与中心服务器间能够高速的存取键值,那么在数据库的选择上,关系型数据库肯定是不行了。高速,多连接,内存存储等需求,那么最适合完成这项任务的就是Redis数据库了。Redis数据库是一个基于内存的高效键值型非关系数据库,存取效率极高,且自带了“集合”数据结构,“集合”数据结构具有不重复特性,可以通过这种结构轻易完成去重操作。看到这里,相信各位已经对于Scrapy对接Redis实现分布式爬取任务有一定的思路了。幸运的是,已经有人实现了这些逻辑和架构,我们可以利用现成的轮子完成这项任务。(本节依然以交易猫网站的游戏商品爬取为例实现Scrapy-redis的分布式爬虫)
0x01 预处理
完成这个项目除了之前用到的库外还需要安装两个库
|
|
其中scrapy_redis库也可以直接去https://github.com/rmax/scrapy-redis 下载代码并移植至工程文件夹,这样方便修改scrapy_redis库中的内容。
0x10 代码实现
0x11 settings.py
更具前面所提到的两个问题,我们需要替换掉默认Scheduler类和去重类,换成scrapy_redis中定义的新类,我们只需要在项目的settings.py中添加两行:
|
|
然后定义redis服务器的IP、端口和密码,有两种方式可以定义:
|
|
然后需要我们关注的是爬取队列的结构。scrapy-redis默认以**优先队列( PriorityQueue )这种方式设置爬取队列,但是,在一些情况下,我们需要以先进先出(Queue)的结构或者先进后出(Stack)**结构设置爬取队列,我们同样也可以在settings.py中设置
|
|
最后要提到的是分布式爬虫防止中断的问题。之前提到过,单台计算机执行scrapy任务时可通过JOBDIR参数保存指定爬取队列和网页指纹,而在基于scrapy-redis的分布式爬虫中几乎不用考虑这个问题,因为爬取队列本身就是利用数据库保存的,如果爬虫中断了,数据库中的Request依然是存在的,下次启动就会接着上次爬虫中断的地方继续爬取。但是值得我们注意的是当非意外的中断爬虫时,Scrapy-Redis默认会清空爬取队列和去重指纹集合,如果我们不想清空,可以通过修改settings.py来配置持久化以实现断点爬取
|
|
0x12 Pipelines.py
Scrapy-Redis实现了一个Pipeline将Item存储到Redis,若是数据量较大通常不会采用这种方法,Redis是基于内存的非关系型数据库,用内存来存储数据着实有些浪费。若是要存储数据通常是先存到各自的计算机上,最后统一合并,或者是再搭建一个MongoDB或Mysql进行存储。
|
|
0x13 Spider.py
在spider的处理上也很简单,只需要修改两处即可。首先要把继承类由原来的scrapy.Spider更换为scrapy-redis中定义的 RedisSpider 类,然后删去start_urls列表,因为初始url框架会从redis数据库中的
|
|
parse()和good_parse()两个函数的逻辑与之前 Scrapy从入门到弃坑(1):框架爬虫爬取交易猫 中两个函数的逻辑完全相同,若不清楚可以前往参考。将代码保存成名为 jiaoym_redis.py ,Spider部分便实现好了。
然后要说说的就是start_urls列表的问题了。因为Scrapy-Redis是通过获取redis数据库中
|
|
0x20 调试、运行与后期优化
分布式爬虫的所有逻辑和设置都已经完全实现了,接下来我们可以运行命令以启动Scrapy
|
|
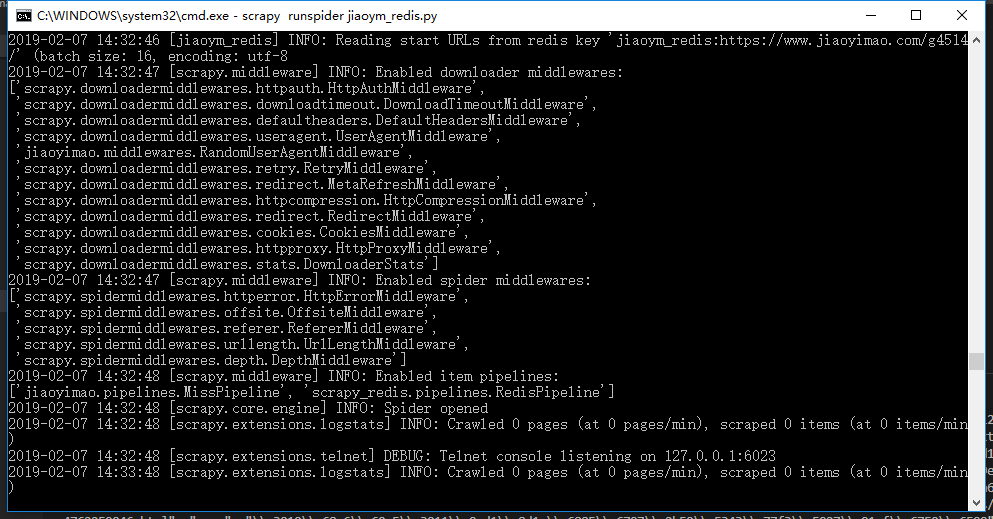
可以看到,Scrapy成功启动并进入等待状态,因为这时候我并没有给 jiaoym_redis:start_urls 列表导入值,一旦lpush了一个start_url给列表,scrapy便会启动工作,获取该url开始爬取。
笔者在实际运行过程中还遇到了这个问题
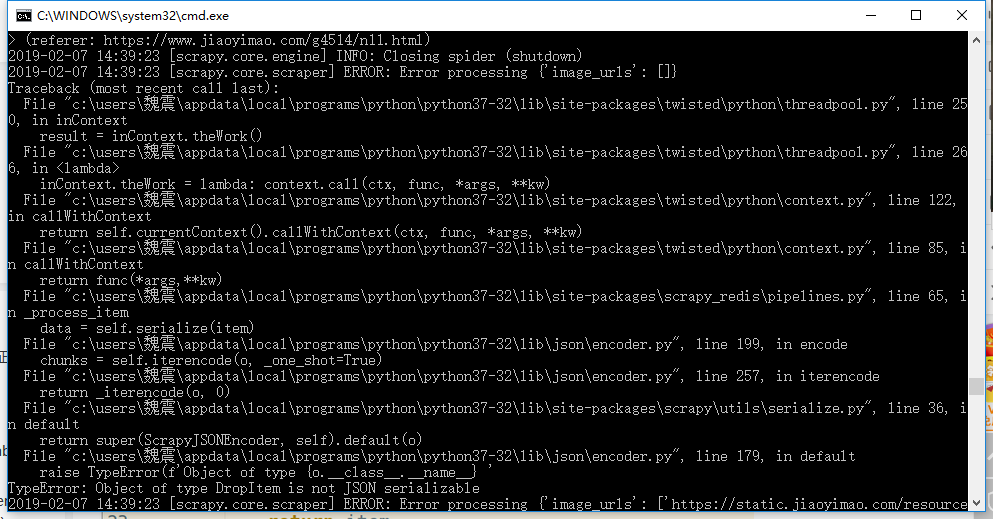
看到提示可以大致了解到是因为DropItem对象无法序列化存入数据库引起的。因为在python中,各个对象其实都是由类生成的实例,但是数据库中是无法存储这种实例的,因此我们需要对其进行序列化,当我们需要这些数据时再从数据库中取出进行反序列化形成对象。但不是所有的数据都能进行序列化的,比如这里的DropItem对象,因为DropItem对象本来就是需要被过滤的,因此我们只需在较高优先级的ItemPipeline中raise掉它们即可。
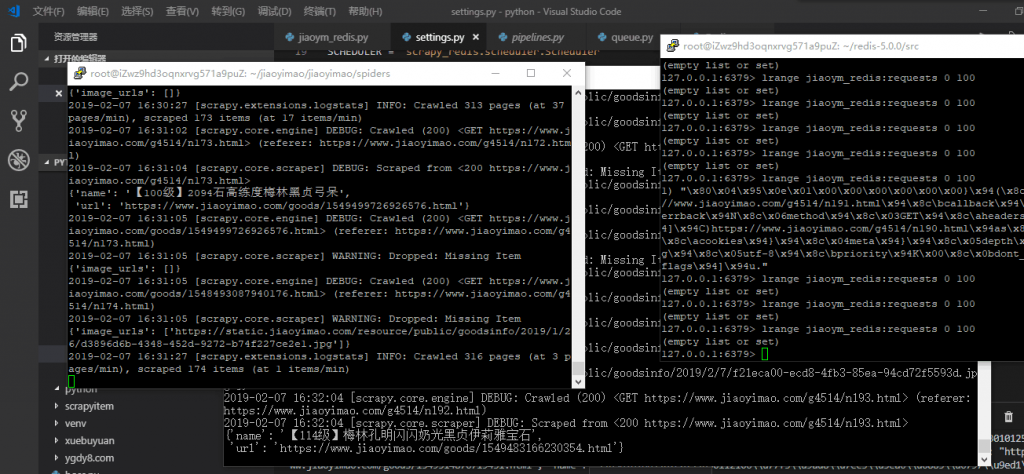
笔者在两台计算机上运行这个爬虫,可以看到分布式实现的非常成功,但是有的时候其中一台计算机会停下来进入等待状态,通过一番排查发现这并不是代码不优化的问题(而是太优化了…),Scrapy本身就是一个异步并发的爬虫框架,在运行时能同时从爬取队列中获取多条requests,也就是说一台计算机想其中push了几条requests后瞬间就将其pop走了,从上图也可看出大部分的时间里 jiaoym_redis:requests 列表时没有数据的,要解决这个问题我们可以增加time.sleep时间以降低单台计算机的爬取速度,或者给两台计算机的两个爬虫实现不同的逻辑(一个从前往后、一个从后往前等)。总而言之,因为运用了多台计算机,带宽大了,其他可调整优化的东西也就多了。
教程到此结束,在下一节中会讲述框架与Bloom Filter(布隆过滤器)的对接以实现一个更优化的去重方案。