这比赛我也是没话说,不知道是不是因为某“鼎尖赛事”中逆向出了问题让某秋被骂的很惨,这次国赛直接放两道签到题。题目数量最少,难度跨度极大,简单题是个人都会做,最后一个难题又偏的不得了(神他妈智能合约逆向),反正感觉这次国赛初赛体验极差
0x01 z3

这题直接Z3一把梭,唯一要注意的时候就是数据提取的时候要小端序整理一下,然后可以在输入这个地方创建以下数组,然后复制出来批量替换v46会比较方便


|
|
0x02 hyperthreading
多线程反调
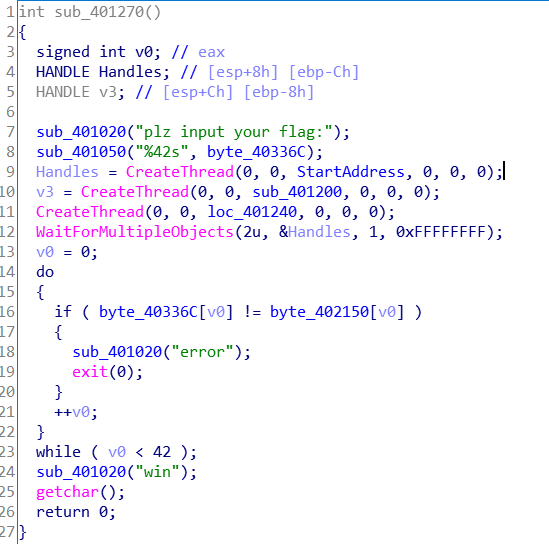
在main函数中可以看到开了3个线程,其中只有第一个线程函数也就是 StartAddress 里面才是真正算法。第二个线程函数 sub_401200 会将输入的每一字节与当前TIB的BingDebugged位相加后保存。因为当程序被调试后,BeingDebugged位为1,与之相加,就会将输入改变掉。这个函数的处理方法有很多种,可以在main函数里直接把这次 CreateThread 整个过程nop掉,也可以将 sub_401200 空间全部nop掉,再不济,最笨的方法就是动调时在 sub_401200 函数开头处下断,然后修改这个线程的TIB.BingDebugged位。 第三条线程 loc_401240 里面其实就是循环调用 IsDebuggerPresent API,如果检测掉调试器就exit。本质上 IsDebuggerPresent 函数也就是检测BingDebugged标志位,但这个有一个注意点,就是这个标志位是线程独立的,也就是说我们不能仅仅修改一处,要把每个线程都改过来。我这里嫌麻烦,直接将该函数 jnz short loc_401247 指令后又添了一条指令 jz short loc_401247,也就是说不管BingDebugged位是否为真都跳转,也就是在这里实现了一个真死循环,从而让反调无效。
然后看算法 里面动调一下把花指令patch一下,可以看到算法是非常简单的,两次移位一次异或一次加法,同样会又BingDebugged位参与运算,这里直接上脚本了

|
|