X86 CPU的三个模式:实模式、保护模式和虚拟8086模式
0x01 段寄存器
通常情况下,我们认为有8个段寄存器,他们分别是
- ES CS SS DS FS GS LDTR TR
其中,后四个寄存器没有处理器定义,是由操作系统运行它们来赋予目的的。
段寄存器具有以下结构
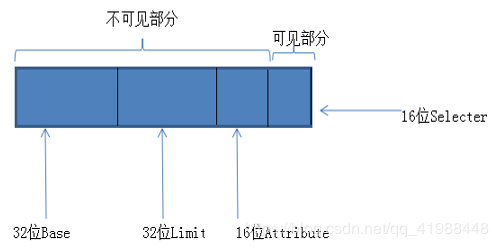
|
|
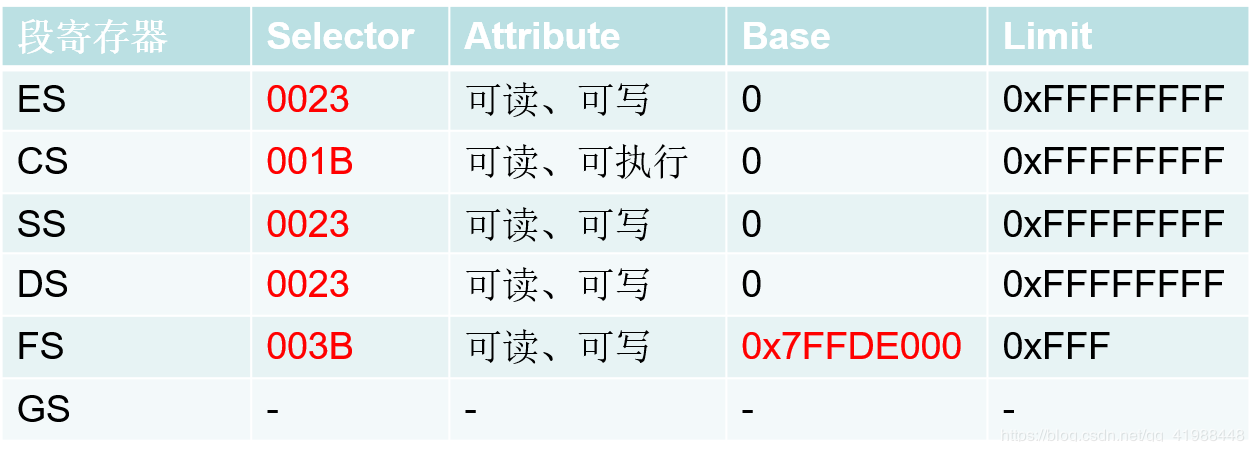
(红色字体视环境而定)
(注意:在64位模式下,Base会占64位,且可由用户设定,且Limit对于所有段寄存器均无效)
在对段寄存器进行读写时,通常我们采用以下格式
读:MOV AX,ES
写:MOV DS,AX
但是从段寄存器结构中我们可以看到,段寄存器有96位,而AX寄存器只有16位,那在读的时候我们可以正常的取低16位(Selector)读入AX,而在写时,就不太一样了,仍然会将96位数据写入Dst,那剩下的80位数据从何而来就是关键了。 在写段寄存器的值时,系统会先取ax的值,拆分出索引位,到gdt表里去找对应的值,最后修改整个Dst的值
0x02 GDT表与LDT表
为了解决上面所说关于剩下80位数据哪里来的问题,就要引入GDT的概念GDT(Global Descriptor Table 全局描述符表)。通常情况下,在设计程序时,我们认为段寄存器为16-bit(虽然每个段寄存器事实上有一个64-bit长的不可见部分,但对于程序员来说,段寄存器就是16-bit),但是为了描述一个段,还需要【Base Address, Limit, Attr】三方面因素,它们加在一起被放在一个64-bit长的数据结构中,被称为段描述符(上面所说的缺少了80位数据,但是这里只存储64位数据是因为80位中只有部分位是有效的)。也就是说,本应该需要64-bit的段寄存器来存储段描述符,但Inter为了向下兼容而规定段寄存器为16-bit,这就需要程序在运行时能通过这16bit数据来找到64bit的段描述符。
怎么解决呢? 解决方法就是将这个64-bit的段描述符放入一个数组中,而将段寄存器中的值作为下标索引来间接引用(事实上,是将段寄存器中的高13 -bit的内容作为索引)。这个全局的数组就是GDT。 但是,GDT这个数组中,存放的不仅仅是段描述符,还有其他的一些64-bit长的描述符。
GDT是Protected Mode所必须的数据结构,也是唯一的。且正如它的名字(GGDTlobal Descriptor Table)所示,它是全局可见的,对任何一个任务而言都是这样。
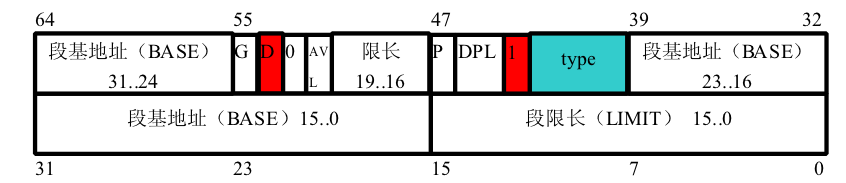
GDT存在哪?怎么找?
GDT可以被放在内存的任何位置,那么当程序员通过段寄存器来引用一个段描述符时,CPU必须知道GDT的入口,也就是基地址放在哪里。这就引入了 GDTR 概念。 为了解决这个问题,Intel的设计者们提供了一个名为GDTR的寄存器用来存放GDT的入口地址,程序员将GDT设定在内存中某个位置之后,可以通过LGDT指令将GDT的入口地址装入此寄存器,从此以后,CPU就根据此寄存器中的内容作为GDT的入口来访问GDT了。
LDT:
除了GDT之外,IA-32还允许程序员构建与GDT类似的数据结构,它们被称作LDT(Local Descriptor Table,局部描述符表),但与GDT不同的是,LDT在系统中可以存在 多个,并且从LDT的名字可以得知,LDT不是全局可见的,它们只对引用它们的任务可见,每个任务最多可以拥有一个LDT。另外,每一个LDT自身作为一个段存在,它们的段描述符被放在GDT中。
LDT只是一个可选的数据结构,你完全可以不用它。使用它或许可以带来一些方便性,但同时也带来复杂性,如果你想让你的OS内核保持简洁性,以及可移植性,则最好不要使用它。
同样的,GDT有GDTR,LDT也有LDTR
IA-32为LDT的入口地址也提供了一个寄存器LDTR,因为在任何时刻只能有一个任务在运行,所以LDT寄存器全局也只需要有一个。如果一个任务拥有自身的LDT,那么当它需要引用自身的LDT时,它需要通过lldt指令将其LDT的段描述符装入此寄存器。lldt指令与lgdt指令不同的时,lgdt指令的操作数是一个32-bit的内存地址,这个内存地址处存放的是一个32-bit GDT的入口地址,以及16-bit的GDT Limit。而lldt指令的操作数是一个16-bit的选择子,这个选择子主要内容是:被装入的LDT的段描述符在GDT中的索引值。
实模式&&保护模式
看到这里,很可能你会有疑惑,在汇编课上,或者开发中,学到的寻址方式就是段基址左移4位+偏移地址,这个段基址也就是段寄存器的值,但是上面的说法却颠覆原来所学的知识。这里就需要补充一下实模式和保护模式的知识。其实这两种说法都是正确的,只是一种是实模式一种是保护模式。保护模式是在实模式上建立起来的,他们有一个区别就是如何得到段基址。实模式是将基址直接存在段寄存器中,而保护模式是将段基址统一存放在表中,这个表就是我们前面所说的GDT和IDT。明白了这个应该能解决不少疑惑。
0x03 段选择子
前面我们说了,我们通过使用段选择子作为索引去GDT/LDT取得保存该段信息的80位数据。那么问题来了,系统该如何区分数据保存在GDT还是LDT,请求的权限是多少,索引值是选择子的一部分还是全部? 这就需要了解段选择子的结构。
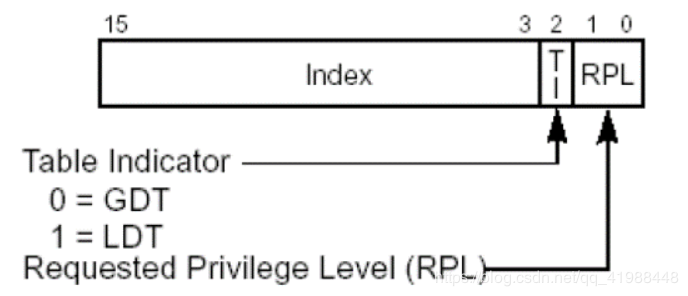
字段说明:
RPL:请求特权级别 (若该段为CS段,则为CPL)
TI:TI=0 查GDT表;TI=1 查LDT表
Index:描述符索引值 处理器将索引值乘以8在加上GDT或者LDT的基地址,就是要加载的段描述符
我们可以看到,Index是表示所需要的段的描述符在描述符表的位置,由这个位置再根据在GDTR/LDTR中存储的描述符表基址就可以找到相应的描述符。然后用描述符表中的段基址加上逻辑地址(SEL:OFFSET)的OFFSET就可以转换成线性地址。
0x04 段与权限
CPU与ring环
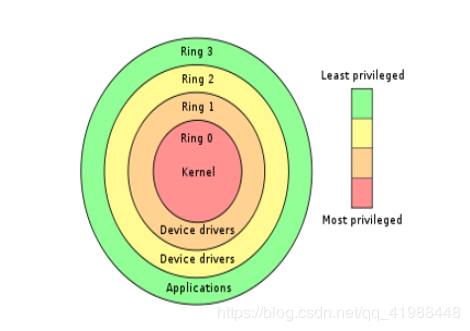
这幅图描述的是CPU的分级概念。一般来说,我们在 Windows 中写的代码,都运行在 3 环(应用层)。只有在调用一些系统接口的时候,或者中断等情况的时候,才会进入 0 环(内核)。也就是为什么平时我们称应用程序为3环,系统程序为0环。
为什么要让CPU给代码赋予不同的权限?这是为了防止你随意更改一些内核中的重要数据,以避免蓝屏。为此,CPU 把执行权限分成了4个等级,0,1,2,3,这就是所谓的ring环, 其中 0 表示最高级,可以执行任意代码,而执行权限为 3 的程序,只能执行普通的指令。Windows 和 Linux 只使用了 0 和 3 这两种。而 CPU 的有些指令和对于某些特殊内存的访问,只能在 0 环执行,这就是所谓的保护。
下面我们需要思考,ring环由什么决定,如何确定某个应用程序是处于哪一环的。
进程特权级别
当前特权级(CPL)
前面在段选择子结构中,我们讲到了 CS寄存器的末两位是CPL,即当前进程的特权级(注意:段选择子SS和CS的后两位比特位相同),而其他段的末两位则是RPL,这也非常好理解,毕竟CS是代码段,运行的程序的代码即在这个段上,这个段已经没有RPL存在的意义了,故此处保存当前进程的特权级最为合适。同时,我们可以理解为是当前正在执行的代码所在的段的特权级,可以看成是段描述符未加载入CS前,该段的DPL,加载入CS后就存入CS的低两位,所以叫做CPL,其值就等于原段DPL的值。
其计算方式如下
→ CS = 0x001B
→ 0x001B = 二进制:0000 0000 0001 1011
→ 二进制:11 = 十进制:3
→ 因此:当前进程处于3环
请求特权级(RPL)
RPL作为段选择子的一部分,是针对段选择子而言的,每个段的选择子都有自己的RPL,其表示用什么权限去访问一个段,也意味着它的改变不会对你所要访问哪个段产生影响(影响你访问哪个段的仅仅由Index决定)。RPL可以实现一些权限的控制,比如当前进程的CPL是0,但我想以一个只读的形式访问一个数据段,就可以用RPL来降低权限(如RPL置3)
MOV AX,0008 // 0000 0000 0000 1000
MOV DS,AX
与
MOV AX,000B // 0000 0000 0000 1011
MOV DS,AX
指向的是同一个段描述符,但RPL不同
段特权级(DPL)
DPL保存在段描述符的段属性中,其规定了访问所在段描述符所需要的特权级别是多少。它与ring环一样,都是数值越大,权限越小。
(注意:在Windows中,DPL只会出现两种情况,要么全为0,要么全为1,即0或3)
数据段权限检查
既然有权限,那就必然会有检查。段的权限检查要求 CPL<= DPL 并且 RPL<= DPL
即段的特权级必然小于等于当前进程的特权级,且我们请求的特权级要大与等于该段的特权级。
数据段权限检查,本质上就是检查能不能把段选择子代入到段寄存器。如果代入成功,表明权限检查通过。如果代入不成功,说明权限不够
0x05 代码跨段跳转
通常,CS寄存器在被载入后,往往不会再去用指令对其值进行修改,同时8086汇编也明确规定了 “除CS外,其他的段寄存器都可以通过MOV,LES,LSS,LDS,LFS,LGS指令进行修改”。那么,为什么CS寄存器不可以直接修改呢?EIP寄存器,记录的其实也是一个偏移,相对于CS的偏移,若是我们对CS进行了修改,改变CS的同时也必须修改EIP,而上述的指令都不具备改变EIP的效果,所以这些指令不能用于CS寄存器。
只改变EIP的指令:
JMP / CALL JCC / RET
同时修改CS与EIP的指令:
JMP FAR / CALL FAR / RETF / INT /IRETED
一致代码段与非一致代码段
在介绍代码段跳转前,需要先了解一下代码段的种类。代码段分为两种,分别是 一致代码段 与 非一致代码段,而且判定依据——“一致位”存在段描述符表示段属性的第五字节上。这里来回头重新看一下段属性
7 6 5 4 3...0
P DPL S TYPE
P:为Persent存在位。1 表示段在内存中存在;0表示段在内存中不存在。
S: 表示描述符的类型。1 数据段和代码段描述符;0 系统段描述符和门描述符
TYPE域:
当S = 1时,即段描述符为代码段或数组段描述符时,Type域结构图如下:
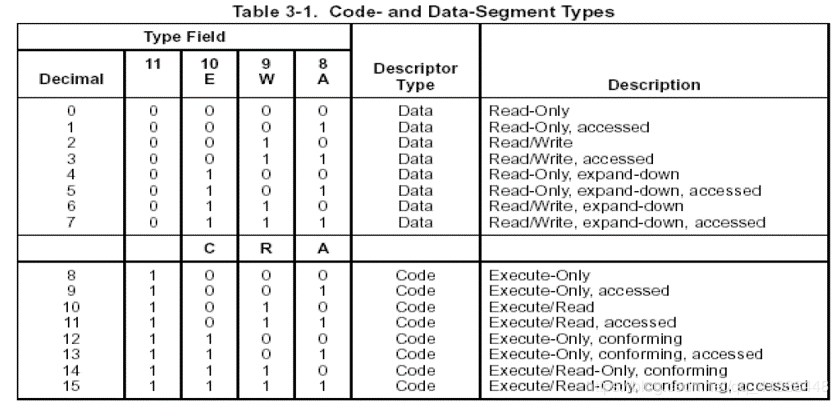
换成人话说,当 S=1 时TYPE中的4个二进制位情况:
3 2 1 0
执行位 一致位(C位) 读写位 访问位
执行位:置1时表示可执行,置0时表示不可执行;
一致位:置1时表示一致码段,置0时表示非一致码段;
读写位:置1时表示可读可写,置0时表示只读;
访问位:置1时表示已访问,置0时表示未访问。
这就非常明显了,是一致代码段还是非一致代码段由一致位是否置1决定。那这两者之间究竟有什么区别呢?
- 一致代码段:简单理解,就是操作系统拿出来被共享的代码段,可以被低特权级的用户直接调用访问的代码。通常这些共享代码,是"不访问"受保护的资源和某些类型异常处理。比如一些数学计算函数库,为纯粹的数学运算计算,被作为一致代码段。如果选择一致代码段,低级别的程序就可以在不提升CPL权限等级的情况下进行访问,并且不会破坏内核态的数据
- 非一致代码段:为了避免低特权级的访问而被操作系统保护起来的系统代码。
- 一致代码段的限制作用:
特权级高的程序不允许访问特权级低的数据:核心态不允许调用用户态的数据.
特权级低的程序可以访问到特权级高的数据.但是特权级不会改变:用户态还是用户态. - 非一致代码段的限制作用:
只允许同级间访问,绝对禁止不同级访问:核心态不用用户态.用户态也不使用核心态. - 权限检查
一致代码段:要求 CPL >= DPL;
非一致代码段:要求 CPL == DPL并且 RPL <= DPL
可以看到,代码段的权限检查与数据段权限检查有很大的区别。数据段不允许低权限对高权限的访问;而代码段不允许高权限对低权限的访问,可视C位是否置1而决定是否允许低权限对高权限的访问。至于为什么会这样,我的理解是不可以将代码段的权限理解为权力,而是安全等级。
代码段是我们所需要运行的,而内核态比用户态更需要安全,如果允许了安全级别更高的代码(内核态)访问了安全级别低的代码(用户态),低安全级别代码的情况对于高安全级别的代码是不清楚的,也就是说,假如用户态的东西有问题,内核态调用了有问题的用户态,就会有崩溃的风险。而用户态调用内核态的代码,必然是用户态确实有这个需求要调用,如果发生了崩溃,那一定是用户态代码存在问题,这样的设计将保证我内核态没有问题。
总结:一致代码段可以当当前特权级低于目标代码段特权级时也可以直接进行跳转,但是不会改变特权级(用户态还是用户态);非一致代码段低特权级程序要跳转到高特权级的代码段需要用过“调用门”等方式暂时提升CPL后才可进行跳转;在代码段的 跳转中 绝对禁止 高特权级程序向低特权级代码段进行跳转(内核态跳至用户态)