Scrapy作为当下最流行的Python框架,本渣也去折腾了一番,也踩了不少坑。在这里分享一下我在使用scrapy框架爬取交易猫时的踩坑之旅。
首先在cmd中进行一波常规操作做一下预处理
- pip install scrapy
- scrapy startproject jiaoyimao
- cd jiaoyimao
- scrapy genspider jiaoym www.jiaouimao.com #注意,爬虫名不得与项目名相同
同时,将settings.py中的ROBOTSTXT_OBEY属性更改为False以忽略目标网站robots.txt文件的限制。
0x00:网站分析
接下来分析网站,可以发现,我们选中一个游戏后并观察源代码可以发现,交易猫把商品的名字和URL都写在了一个标签中,那我们可以直接通过selector提取a标签来筛选获取所需信息。

处理分页问题也非常简单。交易猫网站将总共有多少页写在了页面上,它们的URL均为_…/n<编号>.html_ 我们可以累计这个编号至最后一页来完成爬取任务。还有一种方法便是利用它们的 下一页 功能,递归的构造requst完成爬取。在这里,为了方便大家更好的理解scrapy工作原理,使用第二种方法进行演示。

0x01:items.py
首先确认,我们本次任务是需要获取交易猫网站上符合条件的商品名称和该商品的URL,那么,我们在items.py文件中插入以下内容
|
|
这里我们将url和name定义成了scrapy.Field类型。Field类仅是内置字典类(dict)的一个别名,并没有提供额外的方法和属性。被用来基于类属性的方法来支持item生命语法。当然,只要你喜欢,你也可以用别的数据结构,不影响pipelines和Middlewares的使用。
0x02:spider

接下来处理spider。我们可以看到,框架自动帮我们生成了_start_urls_列表,如果我们没有重写过 _start_requests_方法,框架会自动的从这个列表中获取URL并下载response传给默认的callback函数parse()处理。因为我们爬取的并不是_http://www.jiaoyimao.com/_这个主页,而是类似于_https://www.jiaoyimao.com/g4514/_的页面,所以我们需要修改这个值。但是我希望这个值从settings.py中获取,那样下次我运行爬虫就可以直接修改settings.py运行,而不需要修改spider。 然后….我就开始了我的作死之旅。
首先在jiaoym.py中注释掉start_urls
|
|
然后在settings.py末尾添加
|
|
因为在scrapy中,所有spider都继承了spider.Spider这个父类,这个父类提供了一系列的方法,我们可以使用其中的from_crawler方法获取设置信息并封装成名字为start_urls的成员变量,框架便会提取它来做第一次请求。
###注意,下面的是错误代码做反面教材,请勿使用###
|
|
然后…代码报错。经过一番查询后发现,因为我们继承了spider.Spider这个父类,不支持我们重写__init__方法。

同时还发现了这个错误

没有attribute???这咋整….
这里特别感谢“网络爬虫开发实战读者”群群友_@Liu_提供的技术支持。它将我的代码修改如下
|
|
这里有必要先对super()函数做一个解释。super函数可以很方便的调用父类方法并返回该方法执行后的返回值。关于它的参数,有以下用法:第一个参数总是召唤父类的那个类(可以不用管它的父类是什么了,方便解决多重继承问题),第二个参数可缺(返回非绑定父类对象),也可以是实例对象(self)或该类的子类(cls)。在python3中,我们可以不用填参数,直接用super(),相当于super(type,首参)。
在这里,super()函数解决了无法重写__init__方法的问题。因为没有crawler属性,通过搜索,我们会发现父类中有_set_crawler这个方法。
通过spider._set_crawler(crawler)这个方法,我们可以设置上crawler来解决没有crawler属性的问题。
成功获取到了start_urls列表后,我们就可以开始写parse方法了。
|
|
这里有两处地方需要解释一下。在scrapy中,selector的css选择器是可以混用的,我们可以类似_response.css().xpath()_来嵌套的进行选择。而.extract()方法可以获取该标签的原始数据并以列表的形式返回,.extract_first()方法则获取第一条数据以字符串的形式返回,用这个方法,我们可以很好的解决空标签获取到空列表而导致下标越界的问题。
然后就是 yield scrapy.Request(url=next,callback=self.parse) 这条语句,next是我们匹配得到的下一页的URL,scrapy.Request方法会将其封装成一个request,而callback回调函数则是下载request得到response后处理该response的函数。我曾一度的以为scrapy.Request方法会直接将url做成request发送并立刻执行回调函数以形成一个递归的爬取。这里需要了解一下scrapy工作原理
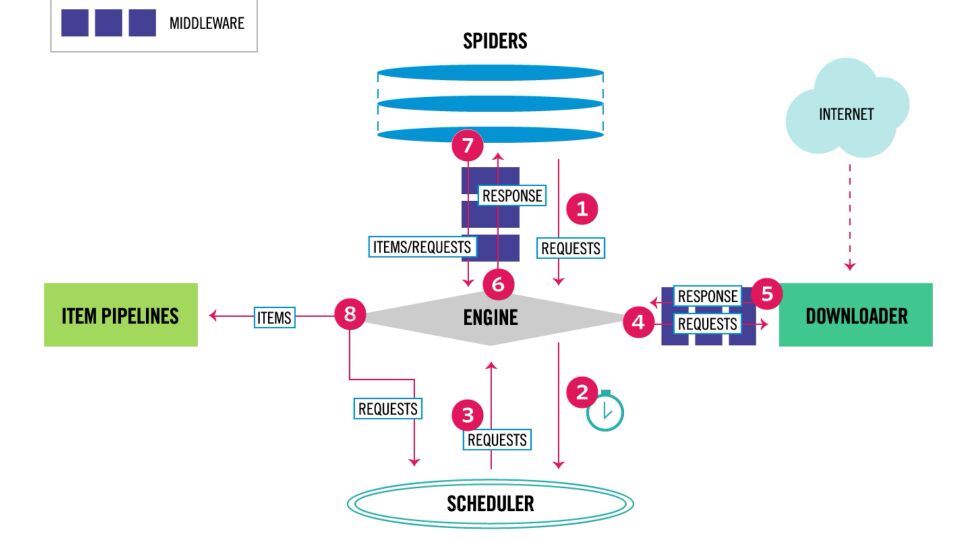

执行scrapy.Request只会将requests发送给Scheduler队列,等到这条requests达到队尾时才会弹出发送给Downloader进行下载。
0x03:pipelines.py
在spiders中,我们通过 _yield items_获取了一组一组的items。通过流程图我们可以看到,这些items会被发送给pipelines进行一个数据清洗,去重,传给数据库等操作。因为我们需要提取的是带有特定条件的商品,比如商品名中含特定的关键字,那么我们便可以写一个pipeline类进行处理。同样的,我们将所需的关键字写成一个列表放在settings.py中
KEYS = [‘梅林’,‘贞德’]
然后再pipelines中进行过滤
|
|
pipeline只能有两种返回值,要么是数据,要么是DropItem异常,我们将不含关键字的商品item进行跳过。
然后,我们也可以在pipeline中连接数据库将商品信息发送到远程数据库。我们现在settings.py中添加redis数据库的登陆信息
|
|
然后再在pipelines.py中写一个类用于传数据。
|
|
最后在settings.py中,将这两个pipeline启动起来,ITEM_PIPELINES字典值越小,该pipeline执行的优先级越高
|
|
0x04:Middlewares.py
Scrapy Middleware分为两种,分别是Downloader Middleware(下载中间件)和Spider Middleware(Spider中间件)。Downloader Middleware(下载中间件)是处于Scrapy的Request和Response之间的处理模块,而Spider Middleware(Spider中间件)是介入到Scrapy的Spider处理机制的钩子框架。通过Scrapy的工作流程图,我们可以看到他的架构。
借助Downloader Middleware,可以实现修改User-Agent,处理重定向,设置代理,失败重试,设置Cookie等功能。而通过Spider Middleware,我们可以中途修改Downloader发送给Spider的Respose,修改Spider发送给Scheduler的Request和发送给Item Pipeline的Item。
关于Scrapy Middlewares的用法和规则,百度上已有很多介绍,这里不再过多阐述,本着以项目为实战的原则,这里实现一个Downloader Middleware类来进行介绍。因为Downloader Middleware具有修改User-Agent的功能,我们在Middlewares.py中写一个名为 RandomUserAgentMiddleware 的类来实现随机获取User-Agent。
|
|
如此如此,我们便通过random库实现了随机选择User-Agent的功能。然后我们同样需要在settings.py中把这个Middleware启动起来。
|
|
最后我们来启动一下爬虫:scrapy crawl jiaoym

甚至scrapy还有内置的参数指定保存requests queue并保留url指纹,这样就支持了断点爬取,万一哪次爬数据时爬到一半跳闸了,或者电脑被女朋友抢走了….我们可以用这个命令
|
|
然后我们就可以发现出现了一个文件夹**crawl/spiders,**这里面保存着requests队列和爬取过的url的指纹,下次如果想接着爬的时候只需要再次执行这个命令,也就是指定队列及指纹保存路径即可实现断点爬取。

Okey!一个基本的Scrapy完成了,各路高手也可以类比着上述方法来优化这个爬虫。不过教程不会到此结束,在下一节,我会介绍Scrapy Item Pipelines的一些高级用法来异步和多线程的下载符合条件的商品的介绍截图。